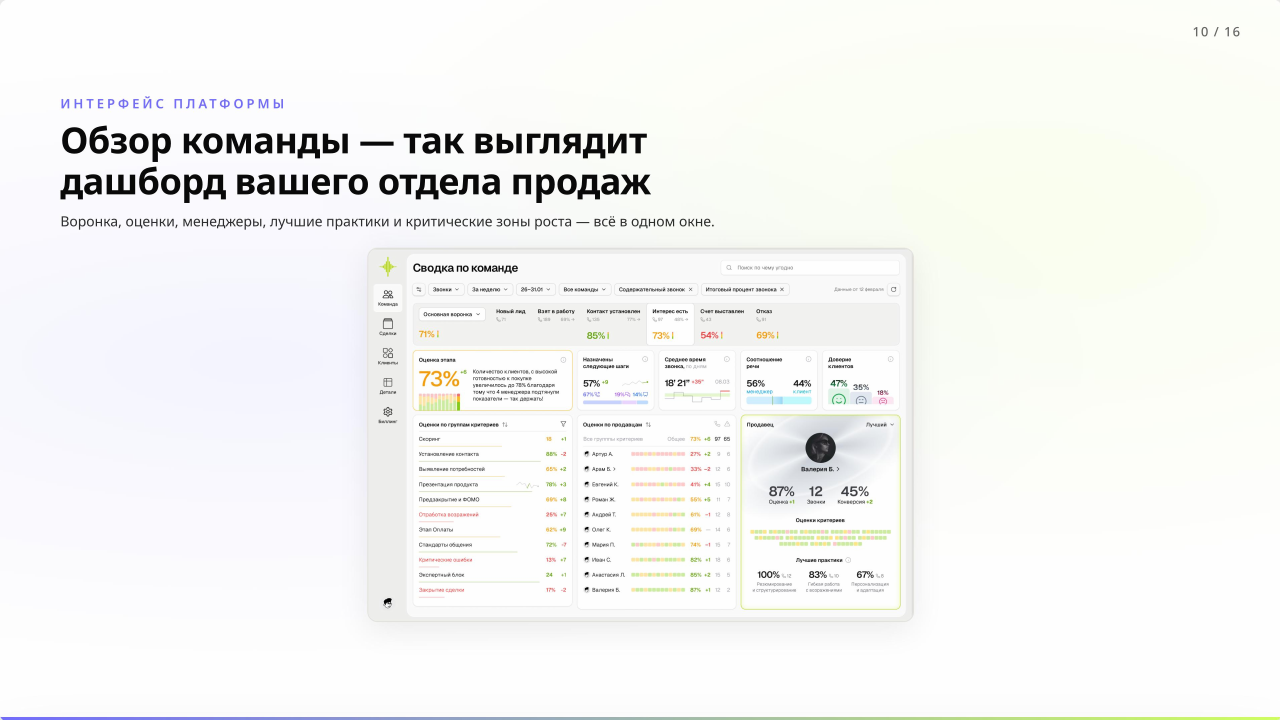
Контекст: знания есть, но «попробуй их найди»
Компания с распределёнными отделами (продажи, юридический, HR, IT, бухгалтерия). У каждого — свой портал, своя файло-помойка, свои Confluence/SharePoint/Notion. У типового сотрудника — 4+ разных места, где «может быть ответ».
Поиск работает по ключевым словам, не по смыслу. Запрос «как оформить командировку для иностранца» ищет точную фразу, не находит — а регламент есть, просто называется «Положение о служебных командировках п. 14.2».
Боль: 4 200 документов, ответ — за 15 минут
Внутренний опрос показал: типовой сотрудник тратит 15 минут на поиск ответа в регламентах. И в 30% случаев находит «не то» или не находит вовсе и идёт спрашивать в чат отдела — отвлекая коллег.
Параллельно появляются «эксперты по регламентам» — сотрудники, которые помнят, где что лежит, и к которым все идут. У них нет рабочего времени на это, и при их отпуске процессы тормозят.
Что сделали: внутренний GPT с RAG-архитектурой
RAG = Retrieval-Augmented Generation. Простыми словами: для каждого ответа AI сначала ищет релевантные фрагменты в базе документов, потом формирует ответ ТОЛЬКО на основе найденного. Не «галлюцинирует», не «думает» от себя.
Загрузили все 4 200 документов в векторную базу: разрезали на смысловые блоки, посчитали эмбеддинги, проиндексировали. На вопрос сотрудника AI достаёт топ-10 релевантных блоков и формирует ответ со ссылками на конкретные документы и пункты.
Главное — данные не уходят к OpenAI. Развернули локальную LLM (на серверах компании или в её Yandex.Cloud), эмбеддинги тоже считаются локально. Чувствительная информация остаётся внутри периметра.
- База: регламенты, инструкции, шаблоны, протоколы, юридические документы
- Каждый ответ — со ссылкой на источник (конкретный документ + раздел)
- On-prem или Yandex.Cloud — без отправки данных в OpenAI / Anthropic
- Ролевой доступ: HR не видит юридическую базу, бухгалтерия не видит HR
- Обновление базы: загружаем новый/изменённый документ — индекс обновляется автоматически
Как работает: типовой запрос
Менеджер пишет в Telegram-боту корпоративного GPT: «Как оформить командировку иностранному сотруднику в Турцию?». Через 6 секунд приходит ответ: «Согласно Положению о служебных командировках (п. 14.2), для иностранного сотрудника требуется: 1) виза (страна назначения), 2) полис ВЗР с покрытием …, 3) согласие отдела HR (через форму X)…».
В конце ответа — ссылка на сам регламент с подсвеченным пунктом. Если сотрудник видит, что AI чего-то не учёл — нажимает «эскалировать в HR», тикет уходит уже с готовым контекстом.
Результат: знания работают
Время поиска ответа упало с 15 минут до 6 секунд. NPS сотрудников по «удобству работы с регламентами» вырос с 4 до 8 (по 10-балльной шкале).
Снизилась нагрузка на «экспертов» — те, к кому раньше шли все, освободили часть рабочего времени. Теперь они занимаются обновлением базы и контролем качества AI-ответов, а не «вопросами как сделать X».